Strategic AI Roadmap Development
We help you build a clear, actionable AI roadmap aligned with your business goals.
Seamless AI Integration and Intelligent Automation
Seamlessly embed AI into your existing workflows for greater efficiency and performance.
Tailored AI Solutions for Industry Challenges
Develop solutions customized to address your unique industry challenges and opportunities.
Workflow Automation Made Smarter
Streamline processes, reduce manual work, and significantly improve overall business efficiency.
Advanced AI Analytics for Insights
Unlock actionable insights from business data to drive faster, smarter, and more impactful decisions.
Generative AI Tools for Content
We help you build a clear, detailed, and actionable AI roadmap fully aligned with your business goals.
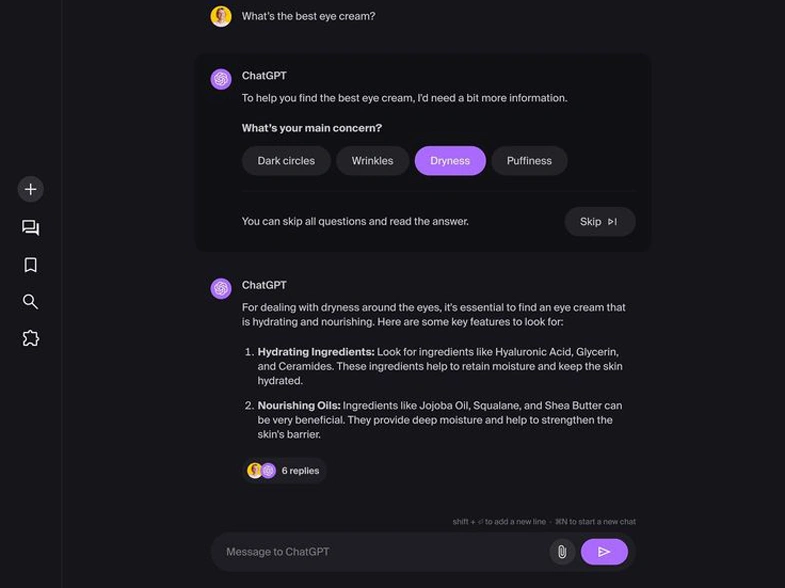

Document Control Use Case ID: `UC-002` Use Case Title: `Intermittent DNS/TLS Incident Diagnosis Across Client Networks` Version: `v1.0` Status: `Approved`…


Jane Dawson
Operations Manager
5.0
Integrating the AI chatbot into our platform reduced our support workload by over 40%. It handles routine queries efficiently, ensures accuracy in responses, and frees our team to focus on innovation.
Emily Carter
Product Manager
5.0
Before working with [AI Startup], managing our workflows was time-consuming and costly. With their AI-powered automation platform, we managed to reduce operational costs by nearly 25% within just three months.
Michael Johnson
Head of Customer Experience
5.0
Our decision criteria were clear: scalability and seamless integration. [AI Startup] delivered both, integrating flawlessly with our operations and accelerating our development timeline by months.

Multi-Channel Chatbots: Connecting with Customers Everywhere
Engage customers seamlessly across websites, mobile apps, and social media, delivering personalized experiences at every touchpoint to…

From Support to Sales: Expanding the Role of Chatbots for Business Growth
Discover how chatbots evolve beyond customer service to become revenue-generating channels—automating lead nurturing, product recommendations, and personalized…

Multi-Channel Chatbots: Engaging Customers Everywhere, Anytime
Deliver consistent conversations across web, apps, and social media for a unified customer experience—ensuring your brand voice…

Unlocking Greater Business Value with AI-Powered Consulting Services
Learn how AI-driven consulting helps companies accelerate growth and create long-term competitive advantages by optimizing decision-making, uncovering…

The Role of Artificial Intelligence in Redefining
Discover how AI-powered chatbots, personalization engines, and predictive analytics are reshaping.

Top 5 Challenges in AI Adoption — And How to Overcome Them
Learn common barriers companies face adopting AI, and strategies to implement solutions successfully.
Document Control Use Case ID: `UC-002` Use Case Title: `Intermittent DNS/TLS Incident Diagnosis Across Client Networks` Version: `v1.0` Status: `Approved`…